Measuring the Web with Lycos
Michael L. Mauldin, Carnegie Mellon University, Pittsburgh, PA, USA
fuzzy@cmu.edu or http://fuzine.vperson.com/mlm/
fuzzy@cmu.edu or http://fuzine.vperson.com/mlm/
- Keywords:
- Web Size, Information Discovery and Retrieval
What is the Web?
The first question to answer in measuring the size of the web is
to determine what counts as being ``on'' the web. We define the
web as any document in either
- FTP space,
- Gopher space, or
- HTTP space.
By design, Lycos does not index ephemeral or changing data or
infinite virtual spaces. Therefore, the following are not considered part
the web:
- WAIS databases
- USENET news
- TELNET services
- Email
Further, we do not consider the output of CGI scripts as part of
our count. To codify this constraint, we ignore URLs containing
either a question mark (?) or an equals-sign (=), as these characters
are of primary usage for CGI scripts. We also eliminate some URLs
such as the human genome database or the Blackbox glossary, which
encodes user state information in the URL
(without this limitation, a robot could count a single page with
state information an infinite number of times).
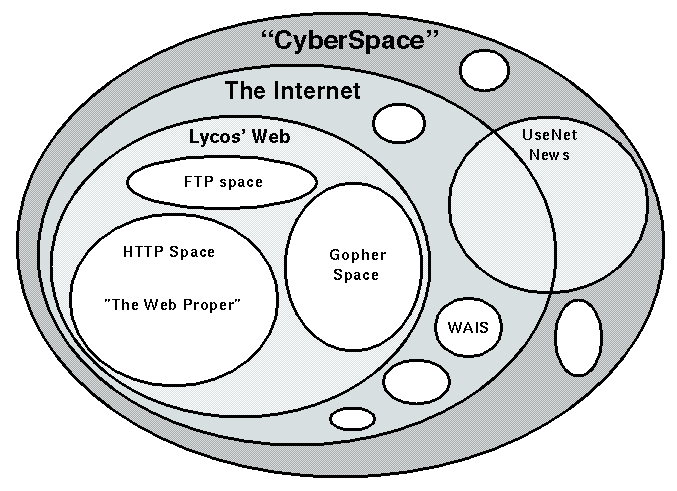
The figure shows our taxonomy of CyberSpace, showing that Lycos'
view of the Web is a strict subset of the Internet, but is larger
than simply the space provided by HTTP servers.
Sampling the space
Lycos samples the web continuously, and the search results are merged
with the catalog weekly. To estimate the size of the web, we take
a week's worth of new searches, assume they are an independent
random sample of the web as a whole, and multiply the old document size
by the ratio of the size of the new sample set to the size of the
intersection of the two sets.
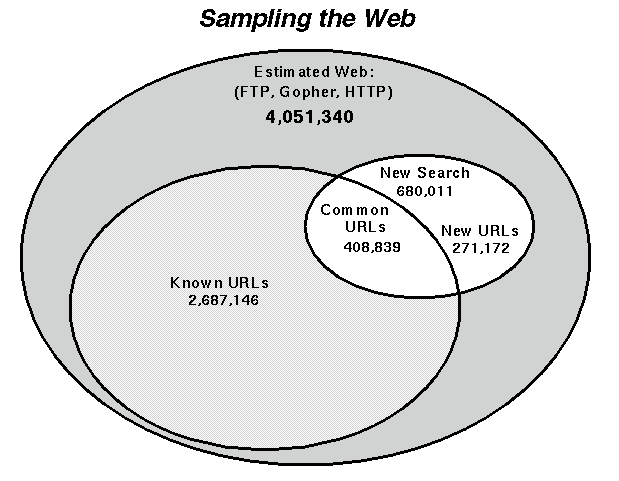
As of April 4th, 1995, the ``old'' document set contained
2,687,146 known URLs. The new search consisted of 680,011 URLs,
of which 408,839 were also in the old set. That gives a ratio
of 1.508, multiplied by the old size gives 4.051 million URLs.
Other Measures
How many servers?
Between Nov 21, 1994 and April 4, 1995, Lycos successfully downloaded at
least one file from 23,550 unique HTTP servers.
What is the distribution of file types?
Cataloged Downloaded
ftp 486906 (16.5%) 31931 ( 6.2%)
gopher 736091 (24.9%) 106340 (20.6%)
http 1722152 (58.2%) 377505 (73.2%)
mailto 276 NA
news 218 NA
rlogin 157 NA
telnet 11401 ( 0.4%) NA
wais 784 NA
total 2957985 515776
How big is the average document?
During that same time period, the average text file size
downloaded was 7,920 characters.
So how big is it?
Multiplying gives an estimate of 32 billion bytes (29.9 gigabytes)
for the size of the web.
Sources of Error
The biggest problem with this number is that the search is almost
certainly not a truly random sample. Lycos uses a biased weighting
scheme to download ``popular'' documents first, so the new search
will tend to overlap the old more than a truly random sample.
Since the size of the intersection is therefore inflated, and
since it's in the denominator, the estimate of 4.051 million is a lower
bound.
Acknowledgements
Lycos is generously supported by funds from Carnegie Mellon University.
Some of the hardware is re-used from the Tipster Data Extraction
Project funded by ARPA. Dr. Mauldin is also funded by a research grant
from the Corporation for National Research Initiatives as part of
ARPA's Computer Science Technical Report project.
Lycos is a registered trademark of Carnegie Mellon University.
Presented at the
Third International World-Wide Web Conference, April 11, 1995.
Last updated 7-Apr-95